
Introduction
Every creation bears the mark of its creator. Artificial intelligence systems are no exception and the algorithms that make them up are inherently riddled with the biases of their coders. Algorithms are just math and code[1], created by people who use our data, so biases that exist in the real world are mimicked or even exaggerated by artificial intelligence systems. This idea is called algorithmic bias in Artificial Intelligence (A.I.) and its perils are of grave concern for humanity.
The Proof of the Bias is in the Testing
It is no secret that artificial intelligence is biased today and ample research has been done to prove this case. Dr. Safia Umoja Noble, a professor at the U.C.L.A. Centre for Critical Internet Inquiry in her book Algorithms of Oppression, discloses some of the results of her six years of academic research into Google algorithms and her detailed insight[2] into the malady of the way ethnic and minority populations are actively discriminated against by the Google Search Engine. Joy Boulamwini, a researcher at the MIT Media Lab who researched on how Artificial Intelligence driven facial-recognition software are programmed to not detect dark-complexioned faces and label faces with the wrong gender[3], forced Google to revamp their A.I. infrastructure in 2020 and give out a public apology. Even Microsoft and IBM have recognised her research as a helping prod into refining their algorithms[4].
Awareness is the Greatest Agent For Change
Most people in the world just have A.I. applied to them, rather than playing an active role in guiding what A.I. gets applied to. Everybody we know has a computer in their pocket; young people, old people, rich people, poor people. Every touch input, every swipe, every keystroke and every click generates data, which is feeding into the A.I. to analyse user behaviour and patterns. It is this data that helps the A.I. to get smarter and be able to get better results. However, we must be aware of at least 5 different types[5] of biases that might creep into the algorithms that collect and analyse our data and be conscious of the ways to mitigate bias in the path of completely eradicating them.
Historical Bias in Training Data
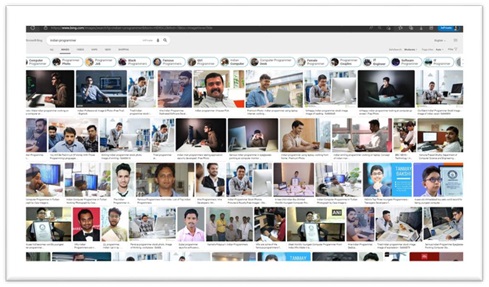
The training data can reflect hidden biases in society. For
example, if an A.I. was trained on news articles or books in India, the word “nurse” is more likely to refer to a
“woman,” while the word “programmer” is more likely to refer to a “man.” You can see this happening with a Google image search: “Indian
nurse” shows mostly women, while “Indian programmer” mostly shows men. We can see how historical biases5 in the training data gets embedded in search engine A.I. Of course, we know there are male nurses and female programmers! A.I. algorithms aren’t very good at recognizing cultural biases that might change over time, and they could even be spreading hidden biases to more human brains. As the internet is now more accessible to children, their minds may be imprinted with these biases that are brought about by the A.I. The solution to this problem is having open access to the algorithms and more inclusive framework in the coding mechanism of the A.I. by minorities and even marginalised sections of society.
Sample Bias
The training data may not have enough examples of each class, which can affect the accuracy of predictions. For example, many facial recognition A.I. algorithms are trained on data that includes way more examples of white peoples’ faces[6] than other races. One story[7] that made the news a few years ago is a passport photo checker with an A.I. system to warn if the person in the photo had blinked or their mouths were open. The system had a lot of trouble with photos of people of Asian and African descent. It kept wrongly flagging dark-skinned people’s lips as an open mouth. Nikon cameras equipped with the blink detection feature also faced similar problems[8] wherein they could not click photos for many of its Asian users because the software thought that their eyes were never open. The way to solve this problem is to have a more comprehensive data set for training data and frequent user testing to keep refining the algorithm.
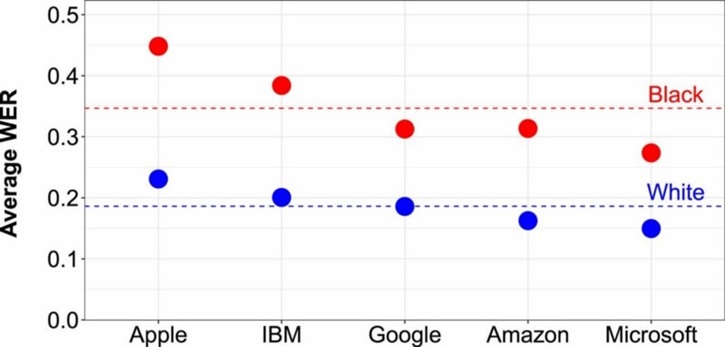
The word error rate (WER) for speech recognition systems from big tech companies clearly depict that all of their voice recognition algorithms underperform for black voices versus the white ones.
Interpretation Bias
It is hard to quantify certain features in training data. There are lots of things that are tough to describe with numbers. In many cases, we try to build A.I. to evaluate complicated qualities of data, but sometimes we have to settle for easily measurable shortcuts. One recent example is trying to use A.I. to grade writing on standardized tests like SATs and GREs with the goal to save human graders time. Good writing involves complex elements like clarity, structure, and creativity, but most of these qualities are hard to measure. So, instead, these A.I. focused on easier-to-measure elements like sentence length, vocabulary, and grammar, which don’t fully represent good writing and made these
A.I.s easier to fool.
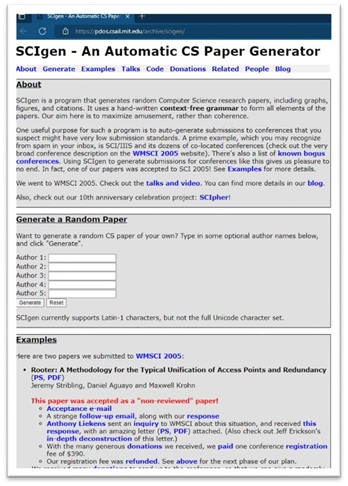
Three students from MIT built a natural language program called SCIgen9 to create essays that made no sense, but were rated highly by these grading
algorithms and even managed to fool scientific
journals. These A.I.s could also potentially be fooled
by memorizing portions of “template” essays to
influence the score, rather than actually writing a response to the prompt, all because of the training
data that was used for these scoring A.I. Apps such as Grammarly can help to mitigate the grammatical errors in a sentence and help to augment a writer’s ability as the A.I. can help spot a spelling or a grammar mistake in a jiffy but being able to assess or grade a poem by E.E. Cummings, would definitely
produce errors of Brobdingnagian proportions.
______________________
9https://news.mit.edu/2015/how-three-mit-students-fooled scientific-journals-0414
10https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-
9713.2016.00960.x
11http://sorelle.friedler.net/papers/feedbackloops_fat18.pdf
Evaluation Bias
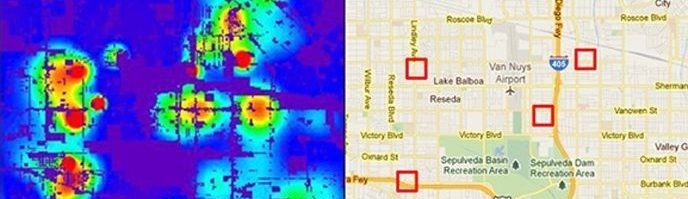
The algorithm could influence the data that it collects, creating a positive feedback loop. A positive feedback loop basically means “amplifying what happened in the past”. In 2016, two researchers[9], the statistician Kristian Lum and the political scientist William Isaac, set out to measure the bias in predictive policing algorithms and chose “PredPol”[10] because their data is available in the public domain. PredPol’s drug crime prediction algorithm, which has been in use since 2012 by the Police in many large cities including L.A. and Chicago, was trained on data that was heavily biased by past housing segregation and past cases of police bias. So, it would more frequently send police to certain neighbourhoods where a lot of racial minority folks lived. Arrests in those neighbourhoods increased, that arrest data was fed back into the algorithm, and the A.I. would predict more future drug arrests in those neighbourhoods and send the police there again. Even though there might be crime in neighbourhoods where police weren’t being sent by this A.I., because there weren’t any arrests in those neighbourhoods, data about them wasn’t fed back into the algorithm. While algorithms like PredPol are still in use, in 2019 the Algorithm Accountability Act was introduced in Congress, which is an important step for monitoring A.I. models and use cases among businesses organizations.
Bias due to Manipulation
Training data may be manipulated on purpose. For example, in 2014, Microsoft released an A.I. chatbot named Xiaoice[11] in China. People could chat with Xiaoice so it would learn how to speak naturally on a variety of topics from these conversations. It worked great, and Xiaoice had over 40 million conversations with no incidents. In 2016, Microsoft tried the same thing in the U.S. by releasing the Twitterbot Tay. Tay trained on direct conversation threads on Twitter, and by playing games with users where they could get it to repeat what they were saying. In 12 hours after its release, after a “coordinated attack by a subset of people”[[12]] [[13]] who biased its data set, Tay started posting violent, sexist, antisemitic, and racist Tweets. This kind of manipulation is usually framed as “joking” or “trolling,” but the fact that A.I. can be manipulated means we should take algorithmic predictions with a grain of salt.
Conclusion
The first step in making A.I. unbiased is collectively understanding and acknowledging that algorithms can be biased. It is crucial to be critical about A.I. recommendations, instead of blindly accepting that “the computer said so.” This is why transparency in algorithms is so important. Transparency from tech-companies is paramount for independent data scientists and researchers to test for bias and point them out. It took over 2400 years for the Hippocratic Oath to transform into the present medical ethics guidelines. Although completely ridding artificial intelligence of any forms of bias may seem impossible today, but so was sending a spacecraft to Mars, a century ago!
{kind=link}